正则学习
正则学习
语法
元字符
| 符号 | 说明 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \s | 匹配任意的空白符 |
| \S | 匹配任意不是空白符的字符 |
| \d | 匹配数字 |
| \D | 匹配任意非数字的字符 |
| [abc] or [a-c] | 匹配括号内的任意字符 |
| [^abc] or [^a-c] | 匹配除了括号内的字符以外的任意字符 |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
限定符
| 符号 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
定位符
| 符号 | 说明 |
|---|---|
| \b | 匹配单词的开始或结束 |
| \B | 匹配不是单词开头或结束的位置 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
修饰符
| 符号 | 说明 |
|---|---|
| i | 忽略大小写 |
| g | 全局匹配,查找所有的匹配项 |
| m | 多行匹配,使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾 |
| s | 默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n |
运算符优先级
| 符号 | 说明 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符及任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,”或”操作,字符具有高于替换运算符的优先级,使得”m|food”匹配”m”或”food”。若要匹配”mood”或”food”,请使用括号创建子表达式,从而产生”(m|f)ood” |
示例
匹配版本号
^\d+(.\d+){2}$
匹配中文
^[\u4e00-\u9fa5]$
匹配图片链接
^(http|https)://(.+/)+.+(.(gif|png|jpg|jpeg|webp|svg|psd|bmp|tif))$
匹配手机号
^1(?:(?:3[\d])|(?:4[5-79])|(?:5[0-35-9])|(?:6[5-7])|(?:7[0-8])|(?:8[\d])|(?:9[189]))\d{8}$
匹配身份证号
^[1-9]\d{5}(?:18|19|20)\d{2}(?:0[1-9]|10|11|12)(?:0[1-9]|[1-2]\d|30|31)\d{3}[\dXx]$
匹配邮箱
^[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
匹配Mac地址
[0-9a-fA-F]{2}(:[0-9a-fA-F]{2}){5}
匹配指定文本
### 1.
### 1.1
### 1.3.4
^###\s(\d+.){1,2}(\d+|)$
匹配并替换指定文本
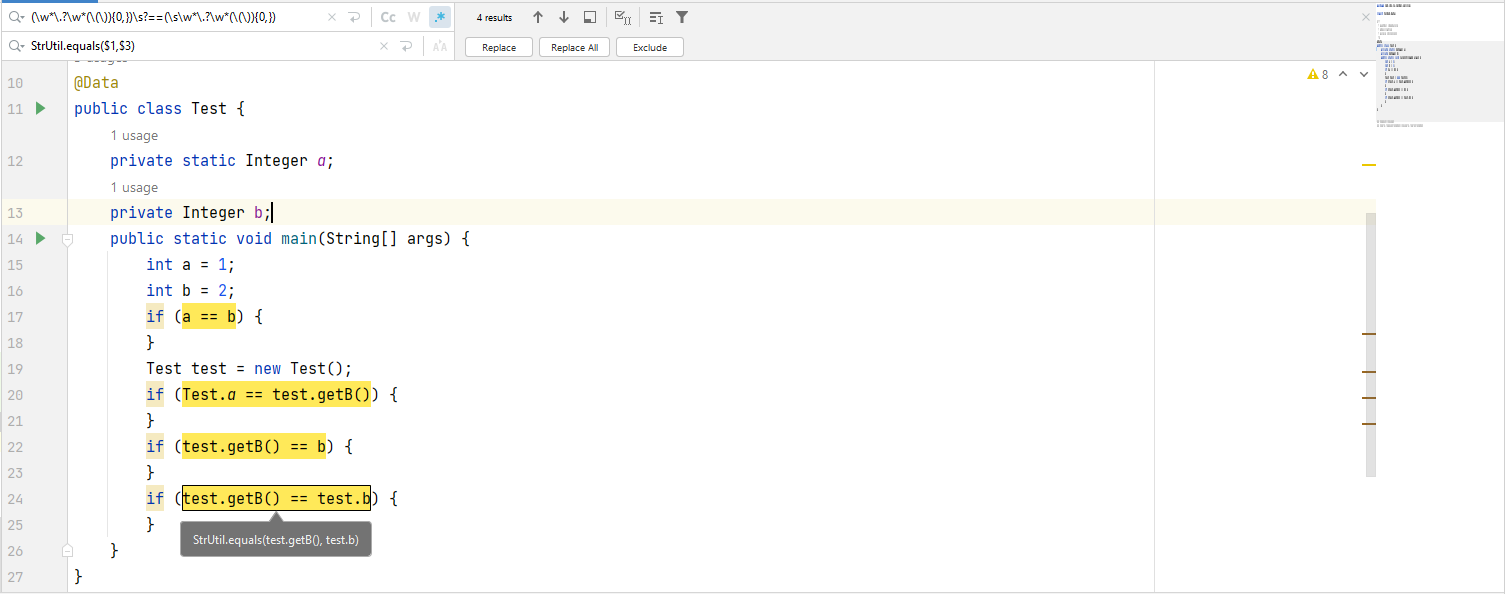
(\w*\.?\w*(\(\)){0,})\s?==(\s\w*\.?\w*(\(\)){0,})StrUtil.equals($1,$3)